6 Probability
Probability
(There was no summary for this lecture.)
(There was no summary for this lecture.)
“The true logic of this world is in the calculus of probabilities.”
—James Clerk Maxwell
6–1Chance and likelihood
“Chance” is a word which is in common use in everyday living. The radio reports speaking of tomorrow’s weather may say: “There is a sixty percent chance of rain.” You might say: “There is a small chance that I shall live to be one hundred years old.” Scientists also use the word chance. A seismologist may be interested in the question: “What is the chance that there will be an earthquake of a certain size in Southern California next year?” A physicist might ask the question: “What is the chance that a particular geiger counter will register twenty counts in the next ten seconds?” A politician or statesman might be interested in the question: “What is the chance that there will be a nuclear war within the next ten years?” You may be interested in the chance that you will learn something from this chapter.
By chance, we mean something like a guess. Why do we make guesses? We make guesses when we wish to make a judgment but have incomplete information or uncertain knowledge. We want to make a guess as to what things are, or what things are likely to happen. Often we wish to make a guess because we have to make a decision. For example: Shall I take my raincoat with me tomorrow? For what earth movement should I design a new building? Shall I build myself a fallout shelter? Shall I change my stand in international negotiations? Shall I go to class today?
Sometimes we make guesses because we wish, with our limited knowledge, to say as much as we can about some situation. Really, any generalization is in the nature of a guess. Any physical theory is a kind of guesswork. There are good guesses and there are bad guesses. The theory of probability is a system for making better guesses. The language of probability allows us to speak quantitatively about some situation which may be highly variable, but which does have some consistent average behavior.
Let us consider the flipping of a coin. If the toss—and the coin—are “honest,” we have no way of knowing what to expect for the outcome of any particular toss. Yet we would feel that in a large number of tosses there should be about equal numbers of heads and tails. We say: “The probability that a toss will land heads is $0.5$.”
We speak of probability only for observations that we contemplate being made in the future. By the “probability” of a particular outcome of an observation we mean our estimate for the most likely fraction of a number of repeated observations that will yield that particular outcome. If we imagine repeating an observation—such as looking at a freshly tossed coin—$N$ times, and if we call $N_A$ our estimate of the most likely number of our observations that will give some specified result $A$, say the result “heads,” then by $P(A)$, the probability of observing $A$, we mean \begin{equation} \label{Eq:I:6:1} P(A)=N_A/N. \end{equation}
Our definition requires several comments. First of all, we may speak of a probability of something happening only if the occurrence is a possible outcome of some repeatable observation. It is not clear that it would make any sense to ask: “What is the probability that there is a ghost in that house?”
You may object that no situation is exactly repeatable. That is right. Every different observation must at least be at a different time or place. All we can say is that the “repeated” observations should, for our intended purposes, appear to be equivalent. We should assume, at least, that each observation was made from an equivalently prepared situation, and especially with the same degree of ignorance at the start. (If we sneak a look at an opponent’s hand in a card game, our estimate of our chances of winning are different than if we do not!)
We should emphasize that $N$ and $N_A$ in Eq. (6.1) are not intended to represent numbers based on actual observations. $N_A$ is our best estimate of what would occur in $N$ imagined observations. Probability depends, therefore, on our knowledge and on our ability to make estimates. In effect, on our common sense! Fortunately, there is a certain amount of agreement in the common sense of many things, so that different people will make the same estimate. Probabilities need not, however, be “absolute” numbers. Since they depend on our ignorance, they may become different if our knowledge changes.
You may have noticed another rather “subjective” aspect of our definition of probability. We have referred to $N_A$ as “our estimate of the most likely number …” We do not mean that we expect to observe exactly $N_A$, but that we expect a number near $N_A$, and that the number $N_A$ is more likely than any other number in the vicinity. If we toss a coin, say, $30$ times, we should expect that the number of heads would not be very likely to be exactly $15$, but rather only some number near to $15$, say $12$, $13$, $14$, $15$, $16$, or $17$. However, if we must choose, we would decide that $15$ heads is more likely than any other number. We would write $P(\text{heads})=0.5$.
Why did we choose $15$ as more likely than any other number? We must have argued with ourselves in the following manner: If the most likely number of heads is $N_H$ in a total number of tosses $N$, then the most likely number of tails $N_T$ is $(N-N_H)$. (We are assuming that every toss gives either heads or tails, and no “other” result!) But if the coin is “honest,” there is no preference for heads or tails. Until we have some reason to think the coin (or toss) is dishonest, we must give equal likelihoods for heads and tails. So we must set $N_T=N_H$. It follows that $N_T=$ $N_H=$ $N/2$, or $P(H)=$ $P(T)=$ $0.5$.
We can generalize our reasoning to any situation in which there are $m$ different but “equivalent” (that is, equally likely) possible results of an observation. If an observation can yield $m$ different results, and we have reason to believe that any one of them is as likely as any other, then the probability of a particular outcome $A$ is $P(A)=1/m$.
If there are seven different-colored balls in an opaque box and we pick one out “at random” (that is, without looking), the probability of getting a ball of a particular color is $\tfrac{1}{7}$. The probability that a “blind draw” from a shuffled deck of $52$ cards will show the ten of hearts is $\tfrac{1}{52}$. The probability of throwing a double-one with dice is $\tfrac{1}{36}$.
In Chapter 5 we described the size of a nucleus in terms of its apparent area, or “cross section.” When we did so we were really talking about probabilities. When we shoot a high-energy particle at a thin slab of material, there is some chance that it will pass right through and some chance that it will hit a nucleus. (Since the nucleus is so small that we cannot see it, we cannot aim right at a nucleus. We must “shoot blind.”) If there are $n$ atoms in our slab and the nucleus of each atom has a cross-sectional area $\sigma$, then the total area “shadowed” by the nuclei is $n\sigma$. In a large number $N$ of random shots, we expect that the number of hits $N_C$ of some nucleus will be in the ratio to $N$ as the shadowed area is to the total area of the slab: \begin{equation} \label{Eq:I:6:2} N_C/N=n\sigma/A. \end{equation} We may say, therefore, that the probability that any one projectile particle will suffer a collision in passing through the slab is \begin{equation} \label{Eq:I:6:3} P_C=\frac{n}{A}\,\sigma, \end{equation} where $n/A$ is the number of atoms per unit area in our slab.
6–2Fluctuations
We would like now to use our ideas about probability to consider in some greater detail the question: “How many heads do I really expect to get if I toss a coin $N$ times?” Before answering the question, however, let us look at what does happen in such an “experiment.” Figure 6–1 shows the results obtained in the first three “runs” of such an experiment in which $N=30$. The sequences of “heads” and “tails” are shown just as they were obtained. The first game gave $11$ heads; the second also $11$; the third $16$. In three trials we did not once get $15$ heads. Should we begin to suspect the coin? Or were we wrong in thinking that the most likely number of “heads” in such a game is $15$? Ninety-seven more runs were made to obtain a total of $100$ experiments of $30$ tosses each. The results of the experiments are given in Table 6–1.1
|
Table 6–1Number of heads in successive trials of 30 tosses of a coin.
| |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| $11$ | $16$ | $17$ | $15$ | $17$ | $16$ | $19$ | $18$ | $15$ | $13$ | $100\text{ trials}$ | |
| $11$ | $17$ | $17$ | $12$ | $20$ | $23$ | $11$ | $16$ | $17$ | $14$ | ||
| $16$ | $12$ | $15$ | $10$ | $18$ | $17$ | $13$ | $15$ | $14$ | $15$ | ||
| $16$ | $12$ | $11$ | $22$ | $12$ | $20$ | $12$ | $15$ | $16$ | $12$ | ||
| $16$ | $10$ | $15$ | $13$ | $14$ | $16$ | $15$ | $16$ | $13$ | $18$ | ||
| $14$ | $14$ | $13$ | $16$ | $15$ | $19$ | $21$ | $14$ | $12$ | $15$ | ||
| $16$ | $11$ | $16$ | $14$ | $17$ | $14$ | $11$ | $16$ | $17$ | $16$ | ||
| $19$ | $15$ | $14$ | $12$ | $18$ | $15$ | $14$ | $21$ | $11$ | $16$ | ||
| $17$ | $17$ | $12$ | $13$ | $14$ | $17$ | $\phantom{1}9$ | $13$ | $19$ | $13$ | ||
| $14$ | $12$ | $15$ | $17$ | $14$ | $10$ | $17$ | $17$ | $12$ | $11$ | ||
Looking at the numbers in Table 6–1, we see that most of the results are “near” $15$, in that they are between $12$ and $18$. We can get a better feeling for the details of these results if we plot a graph of the distribution of the results. We count the number of games in which a score of $k$ was obtained, and plot this number for each $k$. Such a graph is shown in Fig. 6–2. A score of $15$ heads was obtained in $13$ games. A score of $14$ heads was also obtained $13$ times. Scores of $16$ and $17$ were each obtained more than $13$ times. Are we to conclude that there is some bias toward heads? Was our “best estimate” not good enough? Should we conclude now that the “most likely” score for a run of $30$ tosses is really $16$ heads? But wait! In all the games taken together, there were $3000$ tosses. And the total number of heads obtained was $1493$. The fraction of tosses that gave heads is $0.498$, very nearly, but slightly less than half. We should certainly not assume that the probability of throwing heads is greater than $0.5$! The fact that one particular set of observations gave $16$ heads most often, is a fluctuation. We still expect that the most likely number of heads is $15$.
We may ask the question: “What is the probability that a game of $30$ tosses will yield $15$ heads—or $16$, or any other number?” We have said that in a game of one toss, the probability of obtaining one head is $0.5$, and the probability of obtaining no head is $0.5$. In a game of two tosses there are four possible outcomes: $HH$, $HT$, $TH$, $TT$. Since each of these sequences is equally likely, we conclude that (a) the probability of a score of two heads is $\tfrac{1}{4}$, (b) the probability of a score of one head is $\tfrac{2}{4}$, (c) the probability of a zero score is $\tfrac{1}{4}$. There are two ways of obtaining one head, but only one of obtaining either zero or two heads.
Consider now a game of $3$ tosses. The third toss is equally likely to be heads or tails. There is only one way to obtain $3$ heads: we must have obtained $2$ heads on the first two tosses, and then heads on the last. There are, however, three ways of obtaining $2$ heads. We could throw tails after having thrown two heads (one way) or we could throw heads after throwing only one head in the first two tosses (two ways). So for scores of $3$-$H$, $2$-$H$, $1$-$H$, $0$-$H$ we have that the number of equally likely ways is $1$, $3$, $3$, $1$, with a total of $8$ different possible sequences. The probabilities are $\tfrac{1}{8}$, $\tfrac{3}{8}$, $\tfrac{3}{8}$, $\tfrac{1}{8}$.
The argument we have been making can be summarized by a diagram like that in Fig. 6–3. It is clear how the diagram should be continued for games with a larger number of tosses. Figure 6–4 shows such a diagram for a game of $6$ tosses. The number of “ways” to any point on the diagram is just the number of different “paths” (sequences of heads and tails) which can be taken from the starting point. The vertical position gives us the total number of heads thrown. The set of numbers which appears in such a diagram is known as Pascal’s triangle. The numbers are also known as the binomial coefficients, because they also appear in the expansion of $(a+b)^n$. If we call $n$ the number of tosses and $k$ the number of heads thrown, then the numbers in the diagram are usually designated by the symbol $\tbinom{n}{k}$. We may remark in passing that the binomial coefficients can also be computed from \begin{equation} \label{Eq:I:6:4} \binom{n}{k}=\frac{n!}{k!(n-k)!}, \end{equation} where $n!$, called “$n$-factorial,” represents the product $(n)(n-1)(n-2)\dotsm(3)(2)(1)$.
We are now ready to compute the probability $P(k,n)$ of throwing $k$ heads in $n$ tosses, using our definition Eq. (6.1). The total number of possible sequences is $2^n$ (since there are $2$ outcomes for each toss), and the number of ways of obtaining $k$ heads is $\tbinom{n}{k}$, all equally likely, so we have \begin{equation} \label{Eq:I:6:5} P(k,n)=\frac{\tbinom{n}{k}}{2^n}. \end{equation}
Since $P(k,n)$ is the fraction of games which we expect to yield $k$ heads, then in $100$ games we should expect to find $k$ heads $100\cdot P(k,n)$ times. The dashed curve in Fig. 6–2 passes through the points computed from $100\cdot P(k,30)$. We see that we expect to obtain a score of $15$ heads in $14$ or $15$ games, whereas this score was observed in $13$ games. We expect a score of $16$ in $13$ or $14$ games, but we obtained that score in $15$ games. Such fluctuations are “part of the game.”
The method we have just used can be applied to the most general situation in which there are only two possible outcomes of a single observation. Let us designate the two outcomes by $W$ (for “win”) and $L$ (for “lose”). In the general case, the probability of $W$ or $L$ in a single event need not be equal. Let $p$ be the probability of obtaining the result $W$. Then $q$, the probability of $L$, is necessarily $(1-p)$. In a set of $n$ trials, the probability $P(k,n)$ that $W$ will be obtained $k$ times is \begin{equation} \label{Eq:I:6:6} P(k,n)=\tbinom{n}{k}p^kq^{n-k}. \end{equation} This probability function is called the Bernoulli or, also, the binomial probability.
6–3The random walk
There is another interesting problem in which the idea of probability is required. It is the problem of the “random walk.” In its simplest version, we imagine a “game” in which a “player” starts at the point $x=0$ and at each “move” is required to take a step either forward (toward $+x$) or backward (toward $-x$). The choice is to be made randomly, determined, for example, by the toss of a coin. How shall we describe the resulting motion? In its general form the problem is related to the motion of atoms (or other particles) in a gas—called Brownian motion—and also to the combination of errors in measurements. You will see that the random-walk problem is closely related to the coin-tossing problem we have already discussed.
First, let us look at a few examples of a random walk. We may characterize the walker’s progress by the net distance $D_N$ traveled in $N$ steps. We show in the graph of Fig. 6–5 three examples of the path of a random walker. (We have used for the random sequence of choices the results of the coin tosses shown in Fig. 6–1.)
What can we say about such a motion? We might first ask: “How far does he get on the average?” We must expect that his average progress will be zero, since he is equally likely to go either forward or backward. But we have the feeling that as $N$ increases, he is more likely to have strayed farther from the starting point. We might, therefore, ask what is his average distance travelled in absolute value, that is, what is the average of $\abs{D}$. It is, however, more convenient to deal with another measure of “progress,” the square of the distance: $D^2$ is positive for either positive or negative motion, and is therefore a reasonable measure of such random wandering.
We can show that the expected value of $D_N^2$ is just $N$, the number of steps taken. By “expected value” we mean the probable value (our best guess), which we can think of as the expected average behavior in many repeated sequences. We represent such an expected value by $\expval{D_N^2}$, and may refer to it also as the “mean square distance.” After one step, $D^2$ is always $+1$, so we have certainly $\expval{D_1^2}=1$. (All distances will be measured in terms of a unit of one step. We shall not continue to write the units of distance.)
The expected value of $D_N^2$ for $N>1$ can be obtained from $D_{N-1}$. If, after $(N-1)$ steps, we have $D_{N-1}$, then after $N$ steps we have $D_N=D_{N-1}+1$ or $D_N=D_{N-1}-1$. For the squares, \begin{equation} \label{Eq:I:6:7} D_N^2= \begin{cases} D_{N-1}^2+2D_{N-1}+1,\\[2ex] \kern{3.7em}\textit{or}\\[2ex] D_{N-1}^2-2D_{N-1}+1. \end{cases} \end{equation} In a number of independent sequences, we expect to obtain each value one-half of the time, so our average expectation is just the average of the two possible values. The expected value of $D_N^2$ is then $D_{N-1}^2+1$. In general, we should expect for $D_{N-1}^2$ its “expected value” $\expval{D_{N-1}^2}$ (by definition!). So \begin{equation} \label{Eq:I:6:8} \expval{D_N^2}=\expval{D_{N-1}^2}+1. \end{equation}
We have already shown that $\expval{D_1^2}=1$; it follows then that \begin{equation} \label{Eq:I:6:9} \expval{D_N^2}=N, \end{equation} a particularly simple result!
If we wish a number like a distance, rather than a distance squared, to represent the “progress made away from the origin” in a random walk, we can use the “root-mean-square distance” $D_{\text{rms}}$: \begin{equation} \label{Eq:I:6:10} D_{\text{rms}}=\sqrt{\expval{D^2}}=\sqrt{N}. \end{equation}
We have pointed out that the random walk is closely similar in its mathematics to the coin-tossing game we considered at the beginning of the chapter. If we imagine the direction of each step to be in correspondence with the appearance of heads or tails in a coin toss, then $D$ is just $N_H-N_T$, the difference in the number of heads and tails. Since $N_H+N_T=N$, the total number of steps (and tosses), we have $D=2N_H-N$. We have derived earlier an expression for the expected distribution of $N_H$ (also called $k$) and obtained the result of Eq. (6.5). Since $N$ is just a constant, we have the corresponding distribution for $D$. (Since for every head more than $N/2$ there is a tail “missing,” we have the factor of $2$ between $N_H$ and $D$.) The graph of Fig. 6–2 represents the distribution of distances we might get in $30$ random steps (where $k=15$ is to be read $D=0$; $k=16$, $D=2$; etc.).
The variation of $N_H$ from its expected value $N/2$ is \begin{equation} \label{Eq:I:6:11} N_H-\frac{N}{2}=\frac{D}{2}. \end{equation} The rms deviation is \begin{equation} \label{Eq:I:6:12} \biggl(N_H-\frac{N}{2}\biggr)_{\text{rms}}=\tfrac{1}{2}\sqrt{N}. \end{equation}
According to our result for $D_{\text{rms}}$, we expect that the “typical” distance in $30$ steps ought to be $\sqrt{30} \approx 5.5$, or a typical $k$ should be about $5.5/2 = 2.75$ units from $15$. We see that the “width” of the curve in Fig. 6–2, measured from the center, is just about $3$ units, in agreement with this result.
We are now in a position to consider a question we have avoided until now. How shall we tell whether a coin is “honest” or “loaded”? We can give now at least a partial answer. For an honest coin, we expect the fraction of the times heads appears to be $0.5$, that is, \begin{equation} \label{Eq:I:6:13} \frac{\expval{N_H}}{N}=0.5. \end{equation} We also expect an actual $N_H$ to deviate from $N/2$ by about $\sqrt{N}/2$, or the fraction to deviate by \begin{equation*} \frac{1}{N}\,\frac{\sqrt{N}}{2}=\frac{1}{2\sqrt{N}}. \end{equation*} The larger $N$ is, the closer we expect the fraction $N_H/N$ to be to one-half.
In Fig. 6–6 we have plotted the fraction $N_H/N$ for the coin tosses reported earlier in this chapter. We see the tendency for the fraction of heads to approach $0.5$ for large $N$. Unfortunately, for any given run or combination of runs there is no guarantee that the observed deviation will be even near the expected deviation. There is always the finite chance that a large fluctuation—a long string of heads or tails—will give an arbitrarily large deviation. All we can say is that if the deviation is near the expected $1/2\sqrt{N}$ (say within a factor of $2$ or $3$), we have no reason to suspect the honesty of the coin. If it is much larger, we may be suspicious, but cannot prove, that the coin is loaded (or that the tosser is clever!).
We have also not considered how we should treat the case of a “coin” or some similar “chancy” object (say a stone that always lands in either of two positions) that we have good reason to believe should have a different probability for heads and tails. We have defined $P(H)=\expval{N_H}/N$. How shall we know what to expect for $N_H$? In some cases, the best we can do is to observe the number of heads obtained in large numbers of tosses. For want of anything better, we must set $\expval{N_H}=N_H(\text{observed})$. (How could we expect anything else?) We must understand, however, that in such a case a different experiment, or a different observer, might conclude that $P(H)$ was different. We would expect, however, that the various answers should agree within the deviation $1/2\sqrt{N}$ [if $P(H)$ is near one-half]. An experimental physicist usually says that an “experimentally determined” probability has an “error,” and writes \begin{equation} \label{Eq:I:6:14} P(H)=\frac{N_H}{N}\pm\frac{1}{2\sqrt{N}}. \end{equation} There is an implication in such an expression that there is a “true” or “correct” probability which could be computed if we knew enough, and that the observation may be in “error” due to a fluctuation. There is, however, no way to make such thinking logically consistent. It is probably better to realize that the probability concept is in a sense subjective, that it is always based on uncertain knowledge, and that its quantitative evaluation is subject to change as we obtain more information.
6–4A probability distribution
Let us return now to the random walk and consider a modification of it. Suppose that in addition to a random choice of the direction ($+$ or $-$) of each step, the length of each step also varied in some unpredictable way, the only condition being that on the average the step length was one unit. This case is more representative of something like the thermal motion of a molecule in a gas. If we call the length of a step $S$, then $S$ may have any value at all, but most often will be “near” $1$. To be specific, we shall let $\expval{S^2}=1$ or, equivalently, $S_{\text{rms}}=1$. Our derivation for $\expval{D^2}$ would proceed as before except that Eq. (6.8) would be changed now to read \begin{equation} \label{Eq:I:6:15} \expval{D_N^2}=\expval{D_{N-1}^2}+\expval{S^2}=\expval{D_{N-1}^2}+1. \end{equation} We have, as before, that \begin{equation} \label{Eq:I:6:16} \expval{D_N^2}=N. \end{equation}
What would we expect now for the distribution of distances $D$? What is, for example, the probability that $D=0$ after $30$ steps? The answer is zero! The probability is zero that $D$ will be any particular value, since there is no chance at all that the sum of the backward steps (of varying lengths) would exactly equal the sum of forward steps. We cannot plot a graph like that of Fig. 6–2.
We can, however, obtain a representation similar to that of Fig. 6–2, if we ask, not what is the probability of obtaining $D$ exactly equal to $0$, $1$, or $2$, but instead what is the probability of obtaining $D$ near $0$, $1$, or $2$. Let us define $P(x,\Delta x)$ as the probability that $D$ will lie in the interval $\Delta x$ located at $x$ (say from $x$ to $x+\Delta x$). We expect that for small $\Delta x$ the chance of $D$ landing in the interval is proportional to $\Delta x$, the width of the interval. So we can write \begin{equation} \label{Eq:I:6:17} P(x,\Delta x)=p(x)\,\Delta x. \end{equation} The function $p(x)$ is called the probability density.
The form of $p(x)$ will depend on $N$, the number of steps taken, and also on the distribution of individual step lengths. We cannot demonstrate the proofs here, but for large $N$, $p(x)$ is the same for all reasonable distributions in individual step lengths, and depends only on $N$. We plot $p(x)$ for three values of $N$ in Fig. 6–7. You will notice that the “half-widths” (typical spread from $x=0$) of these curves is $\sqrt{N}$, as we have shown it should be.
You may notice also that the value of $p(x)$ near zero is inversely proportional to $\sqrt{N}$. This comes about because the curves are all of a similar shape and their areas under the curves must all be equal. Since $p(x)\,\Delta x$ is the probability of finding $D$ in $\Delta x$ when $\Delta x$ is small, we can determine the chance of finding $D$ somewhere inside an arbitrary interval from $x_1$ to $x_2$, by cutting the interval in a number of small increments $\Delta x$ and evaluating the sum of the terms $p(x)\,\Delta x$ for each increment. The probability that $D$ lands somewhere between $x_1$ and $x_2$, which we may write $P(x_1 < D < x_2)$, is equal to the shaded area in Fig. 6–8. The smaller we take the increments $\Delta x$, the more correct is our result. We can write, therefore, \begin{equation} \label{Eq:I:6:18} P(x_1 < D < x_2)=\sum p(x)\,\Delta x=\int_{x_1}^{x_2}p(x)\,dx. \end{equation} \begin{equation} \begin{gathered} P(x_1 < D < x_2)=\sum p(x)\Delta x\\[1ex] =\int_{x_1}^{x_2}p(x)\,dx. \end{gathered} \label{Eq:I:6:18} \end{equation}
The area under the whole curve is the probability that $D$ lands somewhere (that is, has some value between $x=-\infty$ and $x=+\infty$). That probability is surely $1$. We must have that \begin{equation} \label{Eq:I:6:19} \int_{-\infty}^{+\infty}p(x)\,dx=1. \end{equation} Since the curves in Fig. 6–7 get wider in proportion to $\sqrt{N}$, their heights must be proportional to $1/\sqrt{N}$ to maintain the total area equal to $1$.
The probability density function we have been describing is one that is encountered most commonly. It is known as the normal or Gaussian probability density. It has the mathematical form \begin{equation} \label{Eq:I:6:20} p(x)=\frac{1}{\sigma\sqrt{2\pi}}\,e^{-x^2/2\sigma^2}, \end{equation} where $\sigma$ is called the standard deviation and is given, in our case, by $\sigma=\sqrt{N}$ or, if the rms step size is different from $1$, by $\sigma=\sqrt{N}S_{\text{rms}}$.
We remarked earlier that the motion of a molecule, or of any particle, in a gas is like a random walk. Suppose we open a bottle of an organic compound and let some of its vapor escape into the air. If there are air currents, so that the air is circulating, the currents will also carry the vapor with them. But even in perfectly still air, the vapor will gradually spread out—will diffuse—until it has penetrated throughout the room. We might detect it by its color or odor. The individual molecules of the organic vapor spread out in still air because of the molecular motions caused by collisions with other molecules. If we know the average “step” size, and the number of steps taken per second, we can find the probability that one, or several, molecules will be found at some distance from their starting point after any particular passage of time. As time passes, more steps are taken and the gas spreads out as in the successive curves of Fig. 6–7. In a later chapter, we shall find out how the step sizes and step frequencies are related to the temperature and pressure of a gas.
Earlier, we said that the pressure of a gas is due to the molecules bouncing against the walls of the container. When we come later to make a more quantitative description, we will wish to know how fast the molecules are going when they bounce, since the impact they make will depend on that speed. We cannot, however, speak of the speed of the molecules. It is necessary to use a probability description. A molecule may have any speed, but some speeds are more likely than others. We describe what is going on by saying that the probability that any particular molecule will have a speed between $v$ and $v+\Delta v$ is $p(v)\,\Delta v$, where $p(v)$, a probability density, is a given function of the speed $v$. We shall see later how Maxwell, using common sense and the ideas of probability, was able to find a mathematical expression for $p(v)$. The form2 of the function $p(v)$ is shown in Fig. 6–9. Velocities may have any value, but are most likely to be near the most probable value $v_p$.
We often think of the curve of Fig. 6–9 in a somewhat different way. If we consider the molecules in a typical container (with a volume of, say, one liter), then there are a very large number $N$ of molecules present ($N\approx10^{22}$). Since $p(v)\,\Delta v$ is the probability that one molecule will have its velocity in $\Delta v$, by our definition of probability we mean that the expected number $\expval{\Delta N}$ to be found with a velocity in the interval $\Delta v$ is given by \begin{equation} \label{Eq:I:6:21} \expval{\Delta N}=N\,p(v)\,\Delta v. \end{equation} We call $N\,p(v)$ the “distribution in velocity.” The area under the curve between two velocities $v_1$ and $v_2$, for example the shaded area in Fig. 6–9, represents [for the curve $N\,p(v)$] the expected number of molecules with velocities between $v_1$ and $v_2$. Since with a gas we are usually dealing with large numbers of molecules, we expect the deviations from the expected numbers to be small (like $1/\sqrt{N}$), so we often neglect to say the “expected” number, and say instead: “The number of molecules with velocities between $v_1$ and $v_2$ is the area under the curve.” We should remember, however, that such statements are always about probable numbers.
6–5The uncertainty principle
The ideas of probability are certainly useful in describing the behavior of the $10^{22}$ or so molecules in a sample of a gas, for it is clearly impractical even to attempt to write down the position or velocity of each molecule. When probability was first applied to such problems, it was considered to be a convenience—a way of dealing with very complex situations. We now believe that the ideas of probability are essential to a description of atomic happenings. According to quantum mechanics, the mathematical theory of particles, there is always some uncertainty in the specification of positions and velocities. We can, at best, say that there is a certain probability that any particle will have a position near some coordinate $x$.
We can give a probability density $p_1(x)$, such that $p_1(x)\,\Delta x$ is the probability that the particle will be found between $x$ and $x+\Delta x$. If the particle is reasonably well localized, say near $x_0$, the function $p_1(x)$ might be given by the graph of Fig. 6–10(a). Similarly, we must specify the velocity of the particle by means of a probability density $p_2(v)$, with $p_2(v)\,\Delta v$ the probability that the velocity will be found between $v$ and $v+\Delta v$.
It is one of the fundamental results of quantum mechanics that the two functions $p_1(x)$ and $p_2(v)$ cannot be chosen independently and, in particular, cannot both be made arbitrarily narrow. If we call the typical “width” of the $p_1(x)$ curve $[\Delta x]$, and that of the $p_2(v)$ curve $[\Delta v]$ (as shown in the figure), nature demands that the product of the two widths be at least as big as the number $\hbar/2m$, where $m$ is the mass of the particle. We may write this basic relationship as \begin{equation} \label{Eq:I:6:22} [\Delta x]\cdot[\Delta v]\geq\hbar/2m. \end{equation} This equation is a statement of the Heisenberg uncertainty principle that we mentioned earlier.
Since the right-hand side of Eq. (6.22) is a constant, this equation says that if we try to “pin down” a particle by forcing it to be at a particular place, it ends up by having a high speed. Or if we try to force it to go very slowly, or at a precise velocity, it “spreads out” so that we do not know very well just where it is. Particles behave in a funny way!
The uncertainty principle describes an inherent fuzziness that must exist in any attempt to describe nature. Our most precise description of nature must be in terms of probabilities. There are some people who do not like this way of describing nature. They feel somehow that if they could only tell what is really going on with a particle, they could know its speed and position simultaneously. In the early days of the development of quantum mechanics, Einstein was quite worried about this problem. He used to shake his head and say, “But, surely God does not throw dice in determining how electrons should go!” He worried about that problem for a long time and he probably never really reconciled himself to the fact that this is the best description of nature that one can give. There are still one or two physicists who are working on the problem who have an intuitive conviction that it is possible somehow to describe the world in a different way and that all of this uncertainty about the way things are can be removed. No one has yet been successful.
The necessary uncertainty in our specification of the position of a particle becomes most important when we wish to describe the structure of atoms. In the hydrogen atom, which has a nucleus of one proton with one electron outside of the nucleus, the uncertainty in the position of the electron is as large as the atom itself! We cannot, therefore, properly speak of the electron moving in some “orbit” around the proton. The most we can say is that there is a certain chance $p(r)\,\Delta V$, of observing the electron in an element of volume $\Delta V$ at the distance $r$ from the proton. The probability density $p(r)$ is given by quantum mechanics. For an undisturbed hydrogen atom $p(r)=Ae^{-2r/a}$. The number $a$ is the “typical” radius, where the function is decreasing rapidly. Since there is a small probability of finding the electron at distances from the nucleus much greater than $a$, we may think of $a$ as “the radius of the atom,” about $10^{-10}$ meter.
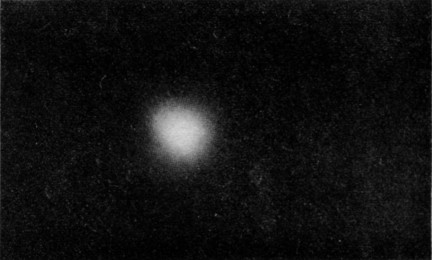
We can form an image of the hydrogen atom by imagining a “cloud” whose density is proportional to the probability density for observing the electron. A sample of such a cloud is shown in Fig. 6–11. Thus our best “picture” of a hydrogen atom is a nucleus surrounded by an “electron cloud” (although we really mean a “probability cloud”). The electron is there somewhere, but nature permits us to know only the chance of finding it at any particular place.
In its efforts to learn as much as possible about nature, modern physics has found that certain things can never be “known” with certainty. Much of our knowledge must always remain uncertain. The most we can know is in terms of probabilities.
- After the first three games, the experiment was actually done by shaking $30$ pennies violently in a box and then counting the number of heads that showed. ↩
- Maxwell’s expression is $p(v)=Cv^2e^{-av^2}$, where $a$ is a constant related to the temperature and $C$ is chosen so that the total probability is one. ↩